Project Rebel Homebase: Teil 5 - Es werde ... Kubernetes!
Vom ersten Herzschlag mit Chrony bis zum 100-Pod-Stresstest: Begleite uns beim Aufbau der Rebel-Infanterie. Ein ehrlicher Guide über Raspberry Pi CM5 Blades, NVMe-Power und die Tücken von Copy & Paste im Kubernetes-Cluster

Heute ein weiterer massiver Milestone in der Rebel Homebase. Das letzte Mal haben wir das Fundament fertig gegossen. DNS, Pi-hole, Zeitserver, das ganze redundant, synchron und wirklich robust. Aber nur 2 Blades? Da gabs doch mehr? Und was ist nun mit den Cluster?
Heute wieder der Rebel-Way der Dokumentation:
Hier gibt es nicht nur das glänzende Endergebnis (und wirklich - was bin ich stolz auf dieses!), sondern den Schweiß und die Stolpersteine auf dem Weg dorthin.
Ein Blog-Artikel, der Fehler und Fixes benennt, und hoffentlich dem einen oder anderen optimistischen Freund der digitalen Souveränität ein bisschen wertvoll sein könnte.
Und wie immer bei den Profis den einen oder anderen herzhaften Lacher hervorbringt.
Vom Master zur Infanterie: Der Aufbau des K3s-Clusters
k3s was? Genau!
Bevor ich die erste Zeile Code auf die 5x CM5-Blades gefeuert habe, stand die alles entscheidende Frage: Die Blades laufen mit Ubuntu. Damit sind alle Devices auf ein und demselben LTS-Standard. Aber welches Betriebssystem für den Cluster?
Die Wahl fiel bewusst auf K3s von Rancher. Und Rancher gehört seit 2020 zu SUSE. Wir bleiben also in Europa. In einer Welt, in der „Standard-Kubernetes“ oft wie ein schwerfälliger Battlestar wirkt, ist K3s die wendige Colonial Viper Mk2:
- Leichtgewicht für ARM: K3s wurde speziell für IoT und Edge-Computing entwickelt. Auf unseren Raspberry Pi CM5-Blades zählt jedes Megabyte RAM. K3s kommt mit einem Bruchteil des Speichers aus, den ein volles K8s verschlingen würde.
- Alles in einer Datei: Anstatt sich mit Dutzenden Binärdateien herumzuschlagen, ist K3s ein einziges, kompaktes Binary (unter 100 MB). Das macht Installation und Updates zum Kinderspiel. Also ich war beeindruckt wie flott das (abzüglich der Zeit die für meine Dummheiten) tatsächlich lief!
- Befreit von Ballast: K3s hat den „Cloud-Provider-Speck“ (wie Treiber für Azure oder AWS) einfach abgeschnitten. Übrig bleibt ein zertifiziertes Kubernetes, das sich perfekt in unser privates Netzwerk integriert, ohne unnötige Hintergrundprozesse. Und diesen Overhead brauchen wir ja in unseren Setting wirklich nicht.
- Produktionsreif: Trotz seiner geringen Größe ist es kein Spielzeug. Es ist die ideale Basis, um später Schwergewichte wie Immich oder Navidrome mit der nötigen Resilienz zu hosten.
Eine kurze Anmerkung: Ich habe ganz großartige Vorschläge von euch zu Skripten, Frameworks und jeder Menge Tools bekommen, die das Setup von Kubernetes besser/einfacher/schneller/professioneller machen. Und ja, ich glaube das ja. Aber hier gehe ich diesen Weg das erste Mal. Zu Fuß. Und ohne Schuhe. Um mal zu sehen wie es ist.
Phase 0: Die Blaupause (Hardware, OS & IP-Strategie)
Bevor der erste Pi Strom bekommt, markieren wir unser Spielfeld. Ein Cluster verzeiht keine spontane IP-Zuweisung. Wir zementieren das gleich richtig. Wir brauchen ein System, das auch nach einem Stromausfall genau weiß, wer der Chef (Master) und wer die Belegschaft (Worker) ist. Und wie die Uhrzeit ist. Wegen der Eigenheit, dass PI's keine gepufferte Uhr haben setzen wir ja unseren redundanten NTP-Server ein.
0.1. Das Betriebssystem: Warum Ubuntu 24.04 LTS?
Wir setzen wie auch vorher auf Ubuntu 24.04.3 LTS (Noble Numbat). [Ein Numbat ist übrigens ein kleines possierliches Beuteltier, wohnhaft in Australien]
- Standard: Fast jede Profi-Dokumentation für Kubernetes oder Apps wie Immich bezieht sich primär auf Ubuntu.
- Langlebigkeit: Wir wollen die Rebel Homebase nicht alle paar Monate neu aufsetzen.
- 64-Bit: Pflicht, um die volle Power der CM5-Architektur zu nutzen.
0.2. Die Speicher-Entscheidung: NVMe statt SD-Card
In der Rebel Homebase gibt es keine langsamen SD-Karten. Jedes CM5-Blade ist mit einer 256 GB NVMe-SSD bestückt (die ultrakompakte Bauform, ca. 30mm lang).
- Speed: NVMe-Speicher bietet Schreib- und Lesegeschwindigkeiten, von denen SD-Karten nur träumen können. Das ist entscheidend für die Kubernetes-Datenbank (etcd) auf dem Master.
- Zuverlässigkeit: SSDs verkraften die ständigen Schreibvorgänge eines Clusters (Logs, Metriken) deutlich besser als Flash-Speicher.
- Vorbereitung: Wir haben die NVMe-Karten direkt mit dem Raspberry Pi Imager vorbereitet. Das Tool erlaubt es uns, Hostnamen, User (
axel), Passwort und SSH-Keys schon vor dem ersten Booten in das Image zu „backen“. Ganz nebensächlich ist es auch noch die bequemste und am wenigsten fehleranfällige Lösung.
0.3. Die IP-Architektur: Schluss mit DHCP- und Namens-Roulette
Damit die Kommunikation stabil bleibt, nutzen wir ein festes IP-Raster für unsere Infrastruktur. Hierbei folgen wir einer strikten Logik: Jeder physische Slot in unserem Blade-System entspricht einem festen Hostnamen und einer festen IP. Das verhindert Verwechslungen, wenn man mal ein Modul tauschen oder physisch auf Fehlersuche gehen muss.
| Hostname | Gerät | IP-Adresse | Rolle |
|---|---|---|---|
| k3s-master | CM4 Blade 3 | 192.168.1.15 | Control-Plane / Gehirn |
| pve-ryzen | Ryzen AI 9 | 192.168.1.16 | Power-Node (Proxmox) |
| k3s-w01 | CM5 Blade 4 | 192.168.1.21 | Worker (Infanterie) |
| k3s-w02 | CM5 Blade 5 | 192.168.1.22 | Worker (Infanterie) |
| k3s-w03 | CM5 Blade 6 | 192.168.1.23 | Worker (Infanterie) |
| k3s-w04 | CM5 Blade 7 | 192.168.1.24 | Worker (Infanterie) |
Tipp: Konfiguriere diese IPs zusätzlich fest in den Netplan-Dateien (/etc/netplan/01-netcfg.yaml) von Ubuntu. So sind die PIs unabhängig vom DHCP-Server deines Routers. Die Anleitung dafür findest Du in Kapitel 3!0.4. Das DNS-Thema: „Wer bin ich – und wenn ja, wie viele?“
Statische IPs in den Netplan-Dateien sind nur die halbe Miete. Damit wir uns im Terminal nicht mit Zahlenreihen quälen müssen, haben wir die Namen in unsere beiden DNS-Server (die wir im Kapital 3 aufgesetzt haben) eingetragen.
- Zentrale Namensauflösung: Jedes Blade ist über seinen Namen (
k3s-w01,k3s-masteretc.) im gesamten Netzwerk erreichbar. Einssh axel@k3s-w03funktioniert sofort, ohne dass wir auf jedem Gerät mühsam die/etc/hosts-Dateien pflegen müssen. - Redundanz: Da wir zwei DNS-Server nutzen, bricht die Namensauflösung im Cluster auch dann nicht zusammen, wenn einer der beiden DNS-Knoten gerade ein Update bekommt.
- Kubernetes-Internals: Auch k3s profitiert davon. Wenn der Master weiß, dass
192.168.1.21unumstößlich zuk3s-w01gehört, minimiert das Timeouts und „Node Not Found“-Fehler bei der Orchestrierung.
Tipp: Wenn du die Namen in deinem DNS pflegst, achte darauf, dass der Hostname im Ubuntu-System exakt mit dem DNS-Eintrag übereinstimmt. Kubernetes reagiert extrem empfindlich auf Diskrepanzen zwischen dem Namen, den das Betriebssystem meldet, und dem Namen, unter dem es im Netz gesucht wird. Jaja, klingt pedantisch, aber glaub mir ...
0.5. Zeit ist alles: Oder wann bin ich?
In der Rebel Homebase überlassen wir nichts dem Zufall. Also auch nicht die Zeit, nicht wahr, Doc Brown? Da wir einen Cluster über mehrere Blades und bald auch den Ryzen-Server betreiben, ist eine absolut synchrone Systemzeit Pflicht.
Anstatt des einfachen Ubuntu-Standards nutzen wir Chrony. Chrony ist robuster, präziser und ideal für Systeme, die ständig laufen.
Unsere NTP-Hierarchie:
- Zentraler Zeitgeber: Unser Infrastruktur-Server auf der 192.168.1.5.
- Vorteil: Alle Blades fragen nur diesen einen Server ab. Das garantiert, dass selbst wenn die Internetverbindung mal hakt, alle Nodes untereinander exakt die gleiche Zeit haben.
Die Konfiguration (Der Homebase-Standard):
Wir installieren Chrony auf jedem Blade (Siehe Teil 4) und binden es exklusiv an unsere interne Quelle.
Die Datei /etc/chrony/chrony.conf (Auszug):
# Alte Pool-Einträge auskommentieren und unsere Quelle setzen
server 192.168.1.5 iburst
# Erlaubt das "Glätten" der Zeit bei Abweichungen (wichtig für K3s)
makestep 1.0 3
Der Beweis (Erfolg): Mit diesem Kommando prüfen wir, ob die Blades brav auf die .5 hören:
chronyc sources -v
Check: In der Liste muss die192.168.1.5mit einem*markiert sein – das Zeichen, dass die Quelle aktiv und synchron ist.>
0.6 Der Headless-Start
Dank der Vorarbeit im Pi-Imager booten die Blades direkt in unser Netz. Kein Monitor, keine Tastatur. Also rein in den Cube, ran an die PoE-Kabel, wir greifen vom ersten Moment an per SSH zu.
Phase 1: Die Vorbereitung (Kernel-Tuning)
Das Problem: Wir installieren K3s auf einem frischen Ubuntu-System auf dem Raspberry Pi, aber der Dienst startet nicht richtig oder Container können ihre Ressourcen nicht limitieren. Ein Blick in die Logs zeigt kryptische Fehler zu „missing cgroups“. Also vor allem Anderen ein Test:
Der "Check":
cat /proc/cgroups | grep memory
Ergebnis: Wenn in der letzten Spalte eine 0 steht, ist das System taub für Speicherlimits – K3s wird hier früher oder später stolpern.
Der Fix: Wir müssen dem Kernel beim Booten sagen, dass er diese Funktionen aktivieren soll.
- Öffne die Boot-Konfiguration:
sudo nano /boot/firmware/cmdline.txt - Füge ans Ende der Zeile (alles muss in einer Zeile bleiben!) diesen String an:
cgroup_enable=cpuset cgroup_memory=1 cgroup_enable=memory
Nochmal: Das muss direkt im Anschluss an die bestehende Zeile hin dran! - Wie immer wichtig: Reboot tut gut!
sudo reboot
Der Beweis (Erfolg): Nach dem Neustart erneut cat /proc/cgroups | grep memory. Jetzt muss dort eine 1 stehen.
Phase 2: Die Grundsteinlegung (CM4 als k3s-master)
Der Plan: Wir wollen einen schlanken Master. Wir verzichten auf den Standard-Ingress (Traefik) und den Standard-Loadbalancer, weil wir später im Proxmox-Ryzen-Kapitel unsere eigene "Schwerlast-Infrastruktur" bauen.
Das Kommando:
curl -sfL https://get.k3s.io | sh -s - server \
--node-name k3s-master \
--bind-address 192.168.1.15 \
--advertise-address 192.168.1.15 \
--node-ip 192.168.1.15 \
--write-kubeconfig-mode 644 \
--disable servicelb \
--disable traefik
--bind-address&--node-ip: Zwingt K3s auf deine statische IP. Ohne das kann es passieren, dass der Master nach einem Neustart plötzlich auf einer internen IP "lauscht", die deine Worker nicht erreichen können.--write-kubeconfig-mode 644: Damit du später mit deinem Useraxel(und Tools wie OpenLens) zugreifen kannst, ohne jedes Malsudovorkubectlschreiben zu müssen.
Hier lief es bei mir mehrfach gegen die Wand. Ich denke, dass einfach der get.k3s.io Server manchmal ganz schön was zu tun hat. Lasst euch hierbei Zeit. Bloß weil nichts passiert heißt es nicht, dass nichts passiert :-)
Testen wir ob dass Nervenzentrum des Clusters schon da ist:
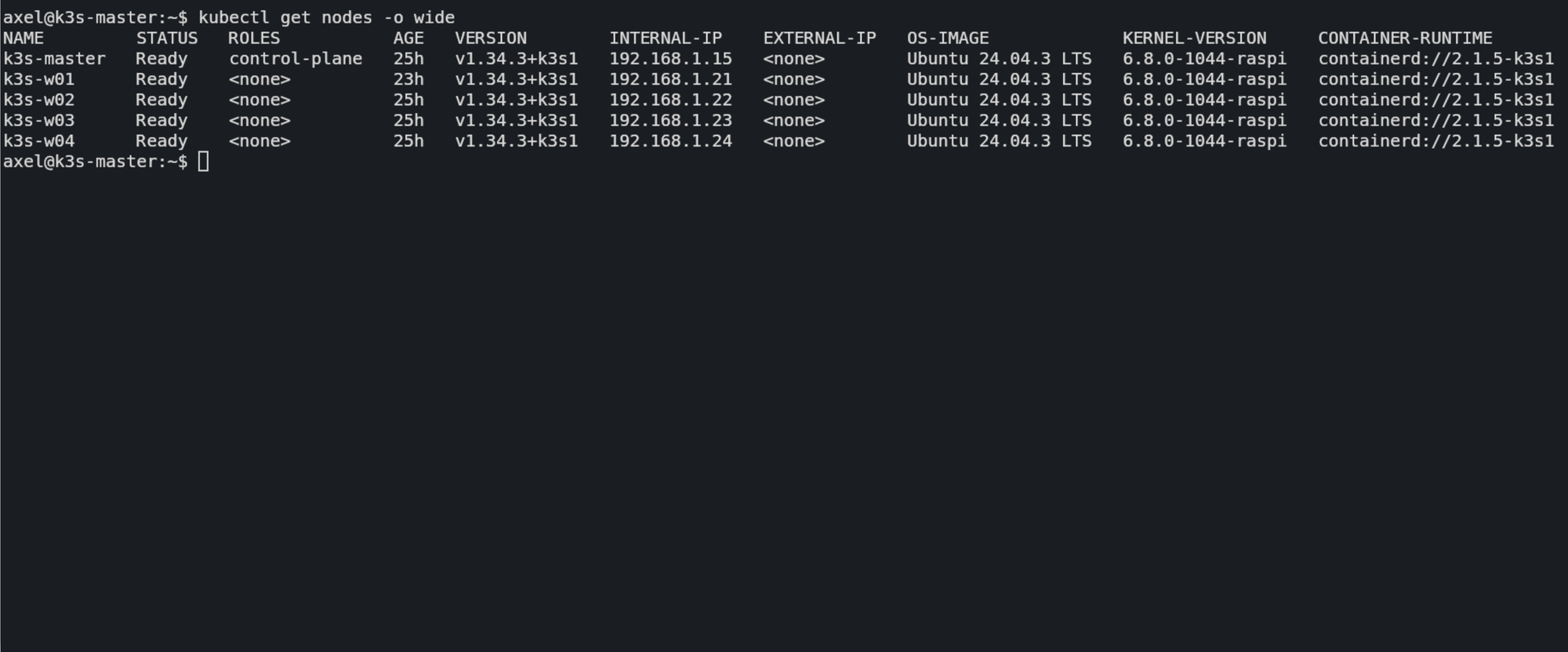
kubectl get nodes -o wide
Das erwartete Ergebnis im Terminal:
NAME STATUS ROLES INTERNAL-IP OS-IMAGE
k3s-master Ready control-plane,master 192.168.1.15 Ubuntu 24.04.3 LTS
Und et voila! Status READY.
Phase 3: Die CM5-Infanterie – Power für die Worker
Nachdem das Gehirn (der Master auf dem CM4) steht, bringen wir jetzt die Muskeln ins Spiel. Während der Master auf einem bewährten Raspberry Pi CM4 läuft, setzen wir bei den Workern auf die neueste Generation: vier Raspberry Pi CM5. Diese Mischbestückung ist ideal: Der Master verwaltet effizient, während die CM5-Blades mit ihrer gesteigerten Performance die eigentliche Arbeit verrichten.
3.1. Die Vorbereitung: NVMe-Power für jeden Worker
Jedes der vier CM5-Module wurde identisch vorbereitet:
- Speicher: 256 GB NVMe (keine SD-Karten!).
- Image: Ubuntu 24.04 LTS via Raspberry Pi Imager.
- Vorkonfiguration: Hostnames (
k3s-w01bisk3s-w04), Useraxelund Passwort - IP-Adressen, DNS und Chrony wie oben bzw. in Teil 3 konfigurieren
Wichtig: Auch auf den Workern müssen die Cgroups in der /boot/firmware/cmdline.txt identisch aktiviert werden (wie in Phase 1 beschrieben), sonst verweigern die CM5-Module später das Ressourcen-Management der Container.
3.2. Der Marschbefehl: Den Cluster betreten
Um die Worker mit dem Master zu verbinden, brauchen wir zwei Dinge vom Master: die IP (192.168.1.15) und das Join-Token. Das ist ein String, der den Schlüssel zum Beitritt für jeden Worker erlaubt. Speichert euch den an einem sicheren Ort (den ihr auch wieder findet)
Kommando auf dem Master, um das Token zu lesen:
sudo cat /var/lib/rancher/k3s/server/node-token
Das Beitritts-Kommando (Beispiel für w01):
Auf jedem Blade führen wir den Befehl mit der jeweils passenden IP aus:
curl -sfL https://get.k3s.io | K3S_URL=https://192.168.1.15:6443 K3S_TOKEN=<DEIN_TOKEN> sh -s - agent \
--node-name k3s-w01 \
--node-ip 192.168.1.21
Achtung! Nicht nur die IP anpassen sondern auch den node-name. Da hatte ich wieder einen Flüchtigkeitsfehler drin, der mich wahnsinnig gemacht hat. Zur Lösung kommen wir gleich
3.3. Der Wahnsinn lag im Copy & Paste
Hier passierte uns der Fehler, der in keinem Handbuch steht, aber jeden Admin trifft. Beim Versuch, die Blades schnell hintereinander in den Cluster zu hieven, schlug die Bequemlichkeit zu.
Das Fehler-Szenario: Beim zweiten Blade wurde zwar der Name im Befehl angepasst, aber die IP-Adresse blieb im Zwischenspeicher der ersten Blade hängen.
- Die Erkenntnis: Kubernetes-Identität basiert auf Eindeutigkeit. Wenn zwei Nodes glauben, sie hätten dieselbe IP, bricht die Kommunikation zusammen.
Mist. Was nun. Master & Blades neu aufsetzen? Bitte nicht. Da ist die wichtigste Lektion in Linux vs. Windows. Bei Windows ist die Neuinstallation der schnellste Fix. Bei Linux kriegst Du wirklich ALLES repariert. Der Zweitname von Linux ist Resilienz!
3.4 Der "HomeBase-Reset": So biegen wir es wieder gerade
Wenn der Copy-Paste-Teufel zugeschlagen hat, hilft kein einfaches Ändern der Konfigurationsdatei. Wir müssen das Blade sauber aus dem Cluster entfernen und neu anmelden.
Der Rettungsweg (bitte Kommando für Kommando):
- Am Master: Die fehlerhaften Nodes löschen, um das Register zu säubern:
kubectl delete node k3s-w01
kubectl delete node k3s-w02
- Am betroffenen Worker: Den K3s-Agenten komplett deinstallieren, damit alle Zertifikate und Zuordnungen gelöscht werden. Wie praktisch. Ein Uninstall-Skript liegt bei:
sudo /usr/local/bin/k3s-agent-uninstall.sh
- Der saubere Neu-Beitritt: Diesmal mit Yogis höchster Konzentration und der korrekten IP-Zuweisung:
curl -sfL https://get.k3s.io | K3S_URL=https://192.168.1.15:6443 K3S_TOKEN=<TOKEN> sh -s - agent \
--node-name k3s-w02 \
--node-ip 192.168.1.22 <--- Jetzt aber!!!
Phase 4: Vitalwerte – Den Puls des Clusters fühlen
Bevor wir die Truppen ins Gefecht schicken, müssen wir sicherstellen, dass das Nervensystem unserer Rebel Homebase einwandfrei funktioniert. In dieser Phase prüfen wir die Einsatzbereitschaft und installieren das „Auge“ des Clusters: den Metrics-Server.
4.1. Der Appell: Sieht der Master seine Truppen?
Der erste Weg führt uns auf das Terminal des Masters (k3s-master). Wir wollen wissen, ob sich alle vier CM5-Worker ordnungsgemäß zum Dienst gemeldet haben.
Das Kommando:
kubectl get nodes -o wide
Worauf du achten musst:
- Status: Alle fünf Einträge (Master + 4 Worker) müssen auf
Readystehen. - Internal-IP: Hier darf kein DHCP-Chaos herrschen. Es müssen exakt die IPs aus der Blaupause (bei mir Master 192.168.1.15 und Worker ab **192.16.1.21 bis .24) zu sehen sein.
- Roles: Der Master zeigt
control-plane,master, die anderen Nodes<none>.
Tipp: Wenn hier ein Node fehlt oder eine falsche IP hat, geh sofort zurück zu Kapitel 3. Ein instabiles Fundament führt später zu Fehlern, die man kaum noch findet. Vertrau mir, Du tust Dir selber einen Gefallen.
4.2. Das Auge des Clusters: Metrics-Server & Der Goldene Patch
Kubernetes ist standardmäßig „blind“. Ohne ein spezielles Tool weiß der Master nicht, wie stark die CPUs der Worker gerade schwitzen. K3s liefert zwar einen Metrics-Server mit, aber in unserem maßgeschneiderten Blade-Netzwerk braucht dieser eine „Brille“, um die Worker-Daten korrekt lesen zu können.
Das Problem: Der Metrics-Server versucht, die Daten sicher abzugreifen, scheitert aber an den selbst signierten Zertifikaten der PIs und weiß oft nicht, über welche IP er sie ansprechen soll.
Der Goldene Patch: Wir führen am Master eine „chirurgische Operation“ am laufenden System durch. Wir patchen das Deployment des Metrics-Servers so, dass er unsichere TLS-Verbindungen intern akzeptiert und strikt unsere Internal-IPs nutzt. Nicht perfekt aber in unserem Netz hier ausreichend
Führe diesen Befehl aus:
kubectl patch deployment metrics-server -n kube-system --type='json' -p='[{"op": "add", "path": "/spec/template/spec/containers/0/args", "value": ["--cert-dir=/tmp", "--secure-port=4443", "--kubelet-preferred-address-types=InternalIP", "--kubelet-use-node-status-port", "--metric-resolution=15s", "--kubelet-insecure-tls"]}]'
4.3. Der Durchblick: Sieht man jetzt die Last?
Nachdem der Patch angewendet wurde, braucht das System etwa 30 bis 60 Sekunden, um den Pod neu zu starten und die ersten Daten zu sammeln. Jetzt schlägt die Stunde der Wahrheit.
Das Kommando:
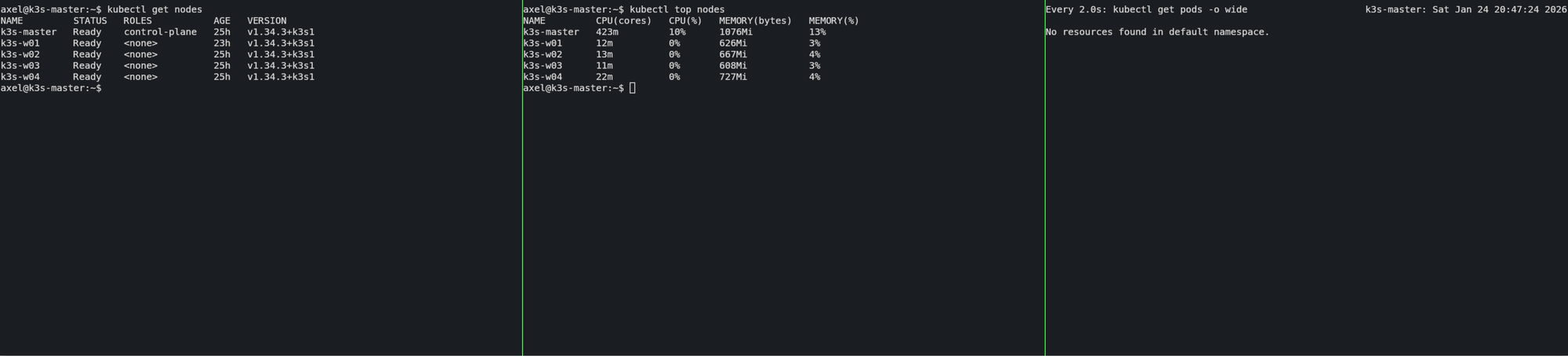
kubectl top nodes
Das Erfolgserlebnis: Wenn du jetzt eine Tabelle siehst, die dir für jeden Node die CPU-Kerne (m), die CPU-Last in % sowie den Speicherverbrauch in MiB und % anzeigt, dann hast du es geschafft!
Meine Erkenntnis: „Ein Cluster ohne funktionierende Metriken ist wie ein Flugzeug ohne Cockpit-Anzeigen. Wir wollen aber keine Fokker DR1 sondern eher sowas wie eine A-10 Warthog. Stichwort Brrrrrr!!! . Jetzt haben wir die volle Kontrolle und können sehen, wie unsere Hardware atmet.
Phase 5: Die Feuertaufe – Stresstest auf Terminal-Ebene
Jetzt wird es ernst, wir machen im wahrsten Sinne des Wortes einmal Dampf. Wir wollen sehen, wie unser CM4-Master die vier CM5-Worker dirigiert, wenn plötzlich massiver Bedarf an Rechenpower entsteht. Wir simulieren einen Ansturm, indem wir 50 Webserver-Instanzen gleichzeitig starten.
5.1. Der Befehl zum Angriff
Wir erstellen ein Deployment namens rebel-website-test mit einem Standard-Nginx-Image.
- Deployment erzeugen:
kubectl create deployment rebel-website-test --image=nginx
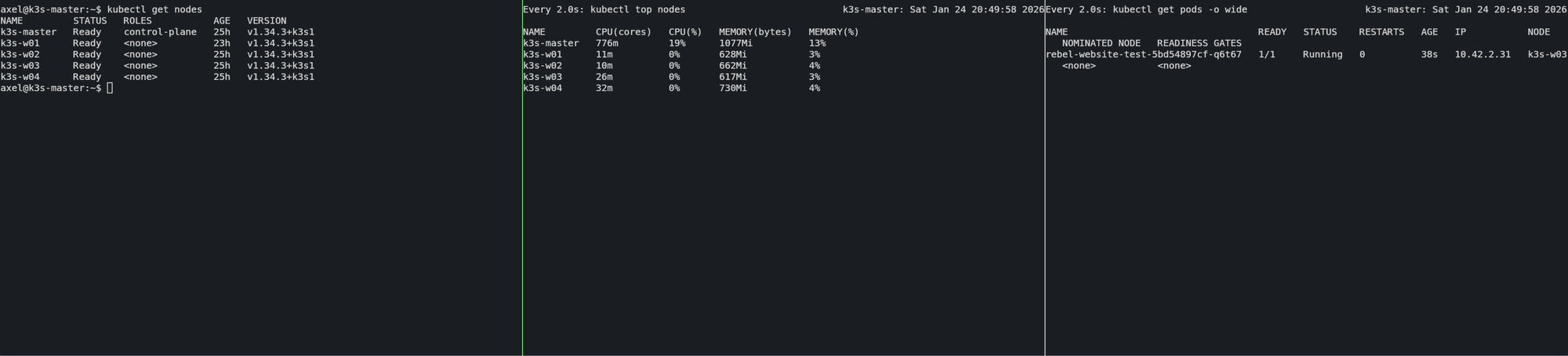
- Die Truppen skalieren (Der eigentliche Stresstest): Wir jagen die Anzahl der Pods von 1 auf 50 hoch. Aufgeregt?
kubectl scale deployment rebel-website-test --replicas=50
5.2. Das Manöver beobachten
In einem zweiten Terminal-Fenster (oder mit dem watch-Befehl) schauen wir zu, wie Kubernetes die Last verteilt:
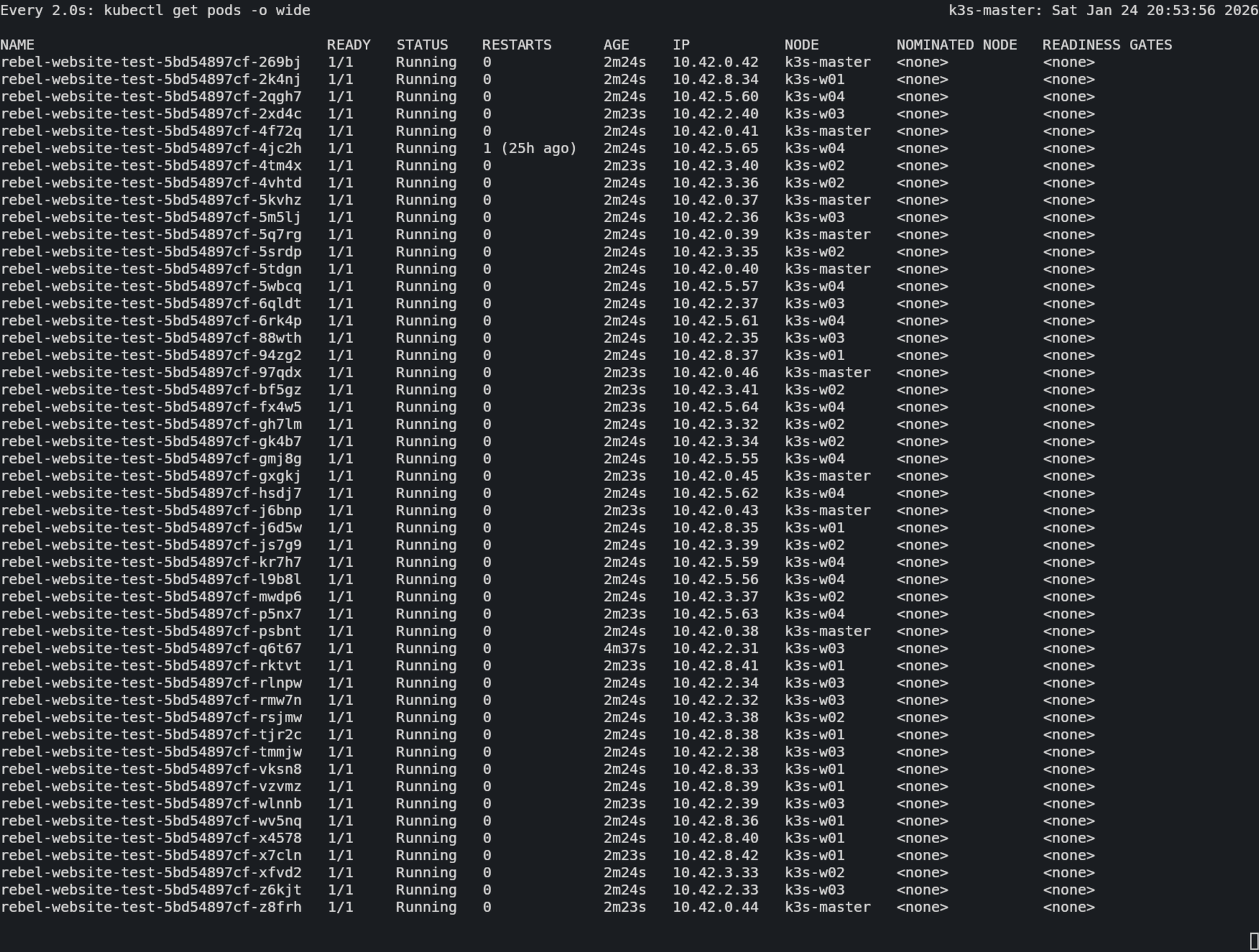
watch kubectl get pods -o wide
Was du jetzt siehst: Es ist ein beeindruckendes Schauspiel. Du siehst, wie die Pods blitzschnell von Pending auf Running springen. Schau dir die Spalte NODE an: Der Master verteilt die 50 Pods gleichmäßig über deine CM5-Infanterie (ca. 10 pro Blade).
5.3. Die Belastung prüfen
Während die 50 Pods hochfahren, tippst du parallel:
watch kubectl top nodes
Die CPU-Werte steigen kurzzeitig an, die Container werden erzeugt , und pendeln sich dann ein. Das nenne ich mal einen Gleichschritt.
Ein gutes Gefühl, oder? Wenn Du so weit gekommen bist (und ich weiss wovon ich spreche) sage ich Dir das ist ein ganz anderes Hochgefühl als "Ich hab da eine virtuelle Maschine auf Azure oder AWS angelegt". :-)
6.0. Für heute aufräumen.
Wir hinterlassen alles wie wir es vorgefunden haben. Das Aufräumen ist fast so "aufregend" wie das Hochskalieren, denn es zeigt, wie effizient Kubernetes Ressourcen wieder freigibt. Sobald du die Befehle abschickst, wirst du in deinen watch-Fenstern ein echtes „Pod-Sterben“ beobachten können.
Hier sind die Kommandos für den Master:
6.1. Den Rückzug antreten (Skalieren auf 0)
Auch wenn wir das Deployment gleich ganz löschen, ist der Zwischenschritt auf 0 interessant für die Beobachtung im Terminal:
kubectl scale deployment rebel-website-test --replicas=0
Im Fenster mit watch kubectl get pods springt der Status aller 100 Pods schnell auf Terminating. Sie verschwinden fast augenblicklich. Ein paart Sekunden später ist die Liste leer. Diese Nginx-Container sind aber auch effizient. Hat da jemand Internet Information Server gesagt?
6.2. Die Spuren verwischen (Deployment löschen)
Jetzt löschen wir das Objekt komplett aus dem Cluster-Gedächtnis.
kubectl delete deployment rebel-website-test
6.3. Ein letzer Blick auf die Vitalwerte
Schau jetzt in dein Fenster mit kubectl top nodes:
- CPU-Last: Diese wird sofort wieder auf den „Idling“-Status (ca. 0-1% bei den Workern) zurückfallen.
- RAM-Verbrauch: pro Blade werden hier schnell einige hundert Megabyte Arbeitsspeicher frei
Ende. Oder?
Fazit
Der Aufbau eines Heim-Clusters ist so gar kein linearer Prozess. Es ist ein Dialogmit dem Cluster. Jeder Fehler (wie der IP-Konflikt oder die fehlenden Metriken) hat mich gezwungen, tiefer in die Mechanik von Kubernetes zu schauen. Jetzt haben wir ein System, das nicht nur läuft, sondern das wir verstehen. Und ...
Wie Botschafter Kosh einst auf Babylon 5 sagte: "And so it begins..."